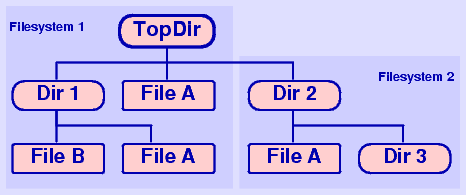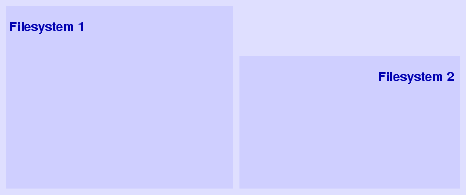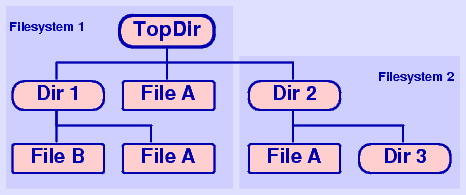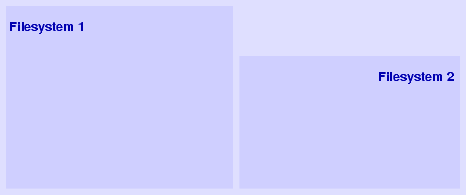
Freedup walks through the file trees (directories) you specify. When it finds two identical files on the same device, it hard links them together. In this case two or more files still exist in their respective directories, but only one copy of the data is stored on disk; both directory entries point to the same data blocks.
If both files reside on different devices, then they are symlinked together except there are relative paths given (and the -s option is unused).
This allows you to reclaim space on your drive. It's that simple. Run it every night from a cron job.
USAGE: freedup [options] [<dir1> ...] -a provide compatibility to freedups by William Stearns.[=-gup] -c count file space savings per linked file. -d requires the modification time stamps to be equal. -f requires the path-stripped file names to be equal. -h shows this help. [other option are ignored] -m <bytes> only touch larger files. (deprecated: use -o "-size +#c") -n do not really perform links [\fBn\fRo action]. -o <opts> pass an option string to the initially called find command. -p requires file permissions to be equal. -s generate symlinks although some given paths are relative. -u requires user & group to be equal. -v display shell commands to perform linking [verbose]. <dir> any directory to scan for duplicate files recursively. Options are toggle switches. Their final state applies. Later <dir> entries are linked to the earlier ones. Providing no <dir2> means to take filenames(!) from stdin. Version 1.0 by Andreas Neuper (c)2007.
| freedup /lib/kbd | (463kB) | |
| freedup /usr/doc /usr/share/doc | ||
| freedup /usr/src/linux-2.6.10 /usr/src/linux-2.6.11 | 20/68329 | (9k) |
| freedup /usr/src/linux-2.6.1* | 930/207000 | (1.52MB) |
| freedup /usr/share | 37/163335 | (2.6MB) |
| freedup /usr/lib | 22/41368 | (97kB) |
| freedup /usr/src/packages/BUILD | 3030/108427 | (17.5MB) |
| freedup /usr/man /usr/share/man | 14/10772 | (19kB) |
| freedup /usr/share/locale /etc/locale | 36/1436 files | (29kB) |
The Frequently Asked Ones are not on this page, since there is an excellent FAQ section on William Stearns freedups page http://www.stearns.org/freedups/README Please note, that freedup is a completely independant implementation, with other means and other capabilities. The Main difference is the ability of freedup to provide symlinks from different file systems.
And here are my questions.
How do you like the performance of freedup?
Are the provided packages what you want?
What about the documentation. Is it sufficient?
Please provide me some feedback here or per mail.
Other similar or related implementations that might be interesting for comparison may be found at Wikipedia.org/wiki/fdupes.
Please send comments, suggestions, bug reports, patches, and/or additions to Andreas Neuper .
I have learned a lot from different web sites. I used William Stearns freedups for many years quite successfully.